|
|
最近,刚跳槽到一新公司,就遇到生产数据库晚上突然出现大面积中断,并持续近一小时,而发生事故时,我没有在现场,错过了直接获取信息的机会;过后boss要求追查原因,于是艰难的排查过程开始了。
开始以为是数据库某个JOB运行出现异常引起或者是因为程序里面哪个鸟人写了垃圾语句造成了大面积的死锁,于是将收集的trace信息拿到本地分析,从收集到的trace信息看,数据库在19:49:28时出现了锁,系统cancel了它,而且是连续三个,之后数据库大部分连接都是Abort了。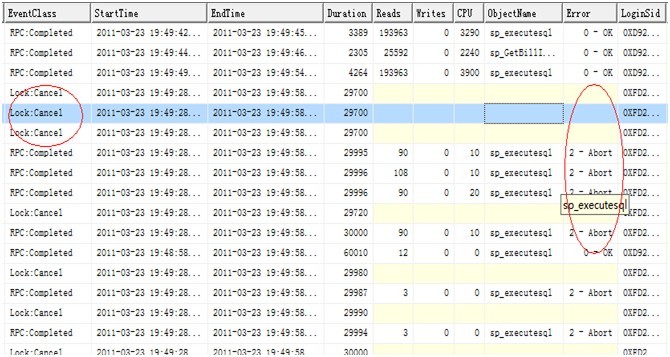 初步估计应该是死锁了,首先想到的就是因为数据库更新语句造成,于是查找Agent里面是否有对应时间的JOB运行,结果没有匹配的,然后分析trace文件里面是否有该时间段内运行的长Update、Insert或者Delete语句,查了半天也没发现,汗。。。,调查长查询,还是没有,狂汗。。。
初步估计应该是死锁了,首先想到的就是因为数据库更新语句造成,于是查找Agent里面是否有对应时间的JOB运行,结果没有匹配的,然后分析trace文件里面是否有该时间段内运行的长Update、Insert或者Delete语句,查了半天也没发现,汗。。。,调查长查询,还是没有,狂汗。。。
Trace文件分析来分析去也没办法定位到具体语句(Trace 文件中只抓取了运行时间超过2秒或者读大于10000的记录),看来问题不是那么简单了;光根据Trace文件信息想要找到凶手估计不可能了,于是把Windows日志和数据库错误日志都查了一遍,也没有发现任何异常,难道是无头案。。。(没查到任何信息,担心饭碗不保了)
想来想去,也问了一些牛人,都没有啥结果,看来通过手头上现有的资料估计要找出问题是没多少希望了,只能另辟蹊径;既然可以肯定是因为死锁造成的,那说明数据库里面肯定存在资源的不一致访问或者竞争,那就从死锁下手,于是先清空掉当前的数据库错误日志文件,再打开1204和1222跟踪标志,等待鱼儿上钩。
DBCC errorlog DBCC TRACEON (1204, 1222, -1); DBCC tracestatus
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。



